
Architecting intelligent systems for performance, reliability, and global deployment
The convergence of artificial intelligence and cloud-native technologies has created unprecedented opportunities for organizations to build, deploy, and scale intelligent applications. But with this opportunity comes complexity—how do you architect AI systems that can handle millions of users, process terabytes of data, and deliver insights in real-time while maintaining cost efficiency and reliability?
This comprehensive guide explores the principles, patterns, and practices for building cloud-native AI solutions that scale from startup MVP to enterprise-grade systems serving global markets.
The future belongs to organizations that can harness AI at cloud scale—those that build intelligence into every interaction, every process, and every decision. - Sundar Pichai, CEO Google
1. Microservices-Based AI Components 🧩
2. Container-First Development 📦
3. API-Driven Integration 🔌
4. Event-Driven Processing ⚡
Kubernetes Orchestration:
# AI Model Deployment Configuration
apiVersion: apps/v1
kind: Deployment
metadata:
name: recommendation-engine
labels:
app: ai-recommendation
version: v2.1
spec:
replicas: 5
selector:
matchLabels:
app: ai-recommendation
template:
metadata:
labels:
app: ai-recommendation
spec:
containers:
- name: recommendation-service
image: ai-registry/recommendation:v2.1
resources:
requests:
memory: 2Gi
cpu: 1000m
nvidia.com/gpu: 1
limits:
memory: 8Gi
cpu: 4000m
nvidia.com/gpu: 1
env:
- name: MODEL_PATH
value: /models/recommendation_v2.1
- name: REDIS_URL
valueFrom:
secretKeyRef:
name: redis-secret
key: urlService Mesh Integration:
Model Serving Platforms:
| Platform | Best For | Key Features | Scale Capacity |
|---|---|---|---|
| KServe | Kubernetes-native | Auto-scaling, multi-framework | 10K+ req/sec |
| Seldon Core | Complex pipelines | Advanced routing, explainability | 50K+ req/sec |
| TorchServe | PyTorch models | Native PyTorch integration | 100K+ req/sec |
| TensorFlow Serving | TensorFlow models | High-performance serving | 200K+ req/sec |
| NVIDIA Triton | Multi-GPU inference | Optimized for GPU workloads | 500K+ req/sec |
Service Decomposition Strategy:
🎯 AI Service Boundaries
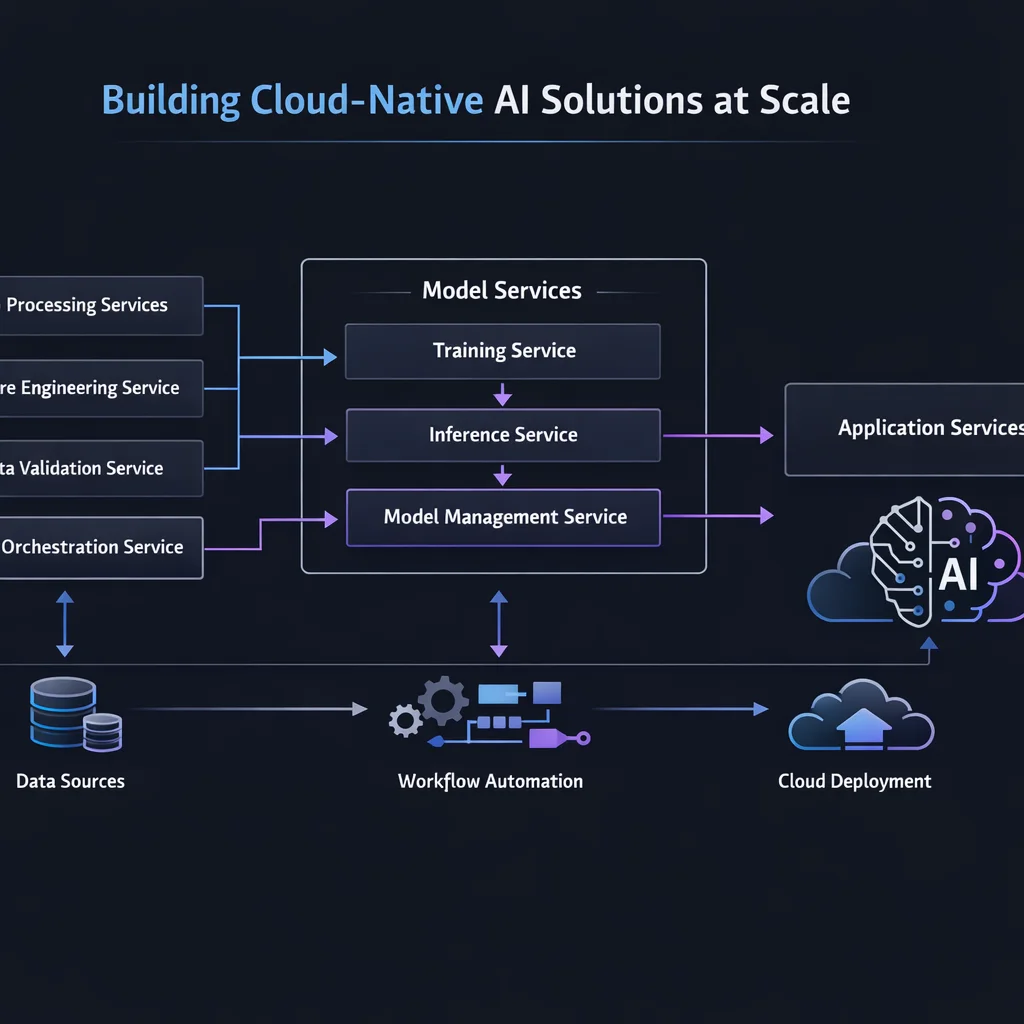Benefits of Microservices AI:
Event Streaming Architecture:
# Apache Kafka Integration for Real-time AI
from kafka import KafkaProducer, KafkaConsumer
import json
import asyncio
class AIEventProcessor:
def __init__(self):
self.producer = KafkaProducer(
bootstrap_servers=[kafka-cluster:9092],
value_serializer=lambda v: json.dumps(v).encode(utf-8)
)
async def process_user_event(self, user_event):
# Extract features for real-time inference
features = self.extract_features(user_event)
# Trigger AI processing
prediction = await self.model_inference(features)
# Publish result to downstream services
result_event = {
user_id: user_event[user_id],
prediction: prediction,
timestamp: user_event[timestamp],
model_version: v2.1
}
self.producer.send(ai-predictions, result_event)
async def model_inference(self, features):
# Call AI model service
async with aiohttp.ClientSession() as session:
async with session.post(
http://model-service/predict,
json={features: features}
) as response:
return await response.json()Tenant Isolation Strategies:
Quantization and Pruning:
import torch
import torch.quantization as quantization
class OptimizedAIModel:
def __init__(self, model_path):
self.model = torch.load(model_path)
def quantize_model(self):
Reduce model size and improve inference speed
self.model.eval()
# Post-training quantization
quantized_model = quantization.quantize_dynamic(
self.model,
{torch.nn.Linear},
dtype=torch.qint8
)
return quantized_model
def optimize_for_inference(self):
Apply TorchScript optimization
traced_model = torch.jit.trace(
self.model,
torch.randn(1, 784) # Example input shape
)
# Further optimization
optimized_model = torch.jit.optimize_for_inference(traced_model)
return optimized_modelCaching Strategies:
# Redis Configuration for Model Caching
apiVersion: v1
kind: ConfigMap
metadata:
name: ai-cache-config
data:
redis.conf: |
maxmemory 8gb
maxmemory-policy allkeys-lru
save 900 1
save 300 10
save 60 10000Horizontal Pod Autoscaler for AI Workloads:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ai-model-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ai-inference-service
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: inference_requests_per_second
target:
type: AverageValue
averageValue: 100Centralized Feature Management:
from feast import FeatureStore
import pandas as pd
class CloudNativeFeatureStore:
def __init__(self):
self.store = FeatureStore(repo_path=.)
def register_features(self):
Register feature definitions
feature_definition =
from feast import Entity, Feature, FeatureView, ValueType
from feast.data_source import BigQuerySource
user_entity = Entity(
name=user_id,
value_type=ValueType.INT64,
description=User identifier
)
user_features = FeatureView(
name=user_activity_features,
entities=[user_id],
ttl=timedelta(days=1),
features=[
Feature(page_views_7d, ValueType.INT64),
Feature(purchases_30d, ValueType.INT64),
Feature(avg_session_duration, ValueType.DOUBLE),
],
batch_source=BigQuerySource(
table_ref=project.dataset.user_features
)
)
async def get_online_features(self, entity_ids):
Retrieve features for real-time inference
feature_vector = await self.store.get_online_features(
features=[
user_activity_features:page_views_7d,
user_activity_features:purchases_30d,
user_activity_features:avg_session_duration
],
entity_rows=[{user_id: uid} for uid in entity_ids]
)
return feature_vector.to_dict()Model Protection Strategies:
# Network Policies for AI Services
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ai-model-security
spec:
podSelector:
matchLabels:
tier: ai-inference
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
name: api-gateway
- podSelector:
matchLabels:
app: load-balancer
ports:
- protocol: TCP
port: 8080
egress:
- to:
- namespaceSelector:
matchLabels:
name: data-services
ports:
- protocol: TCP
port: 5432 # Database
- to:
- namespaceSelector:
matchLabels:
name: feature-store
ports:
- protocol: TCP
port: 6379 # RedisPrometheus Metrics for AI Models:
from prometheus_client import Counter, Histogram, Gauge, start_http_server
class AIModelMetrics:
def __init__(self):
# Model performance metrics
self.prediction_requests = Counter(
ai_prediction_requests_total,
Total prediction requests,
[model_name, version]
)
self.prediction_latency = Histogram(
ai_prediction_duration_seconds,
Prediction latency,
[model_name, version],
buckets=[0.1, 0.5, 1.0, 2.0, 5.0]
)
self.model_accuracy = Gauge(
ai_model_accuracy,
Current model accuracy,
[model_name, version]
)
self.prediction_errors = Counter(
ai_prediction_errors_total,
Prediction errors,
[model_name, version, error_type]
)
def record_prediction(self, model_name, version, latency, accuracy=None):
Record prediction metrics
self.prediction_requests.labels(
model_name=model_name,
version=version
).inc()
self.prediction_latency.labels(
model_name=model_name,
version=version
).observe(latency)
if accuracy:
self.model_accuracy.labels(
model_name=model_name,
version=version
).set(accuracy)Scale Requirements:
Architecture Solution:
🏗️ Architecture Components
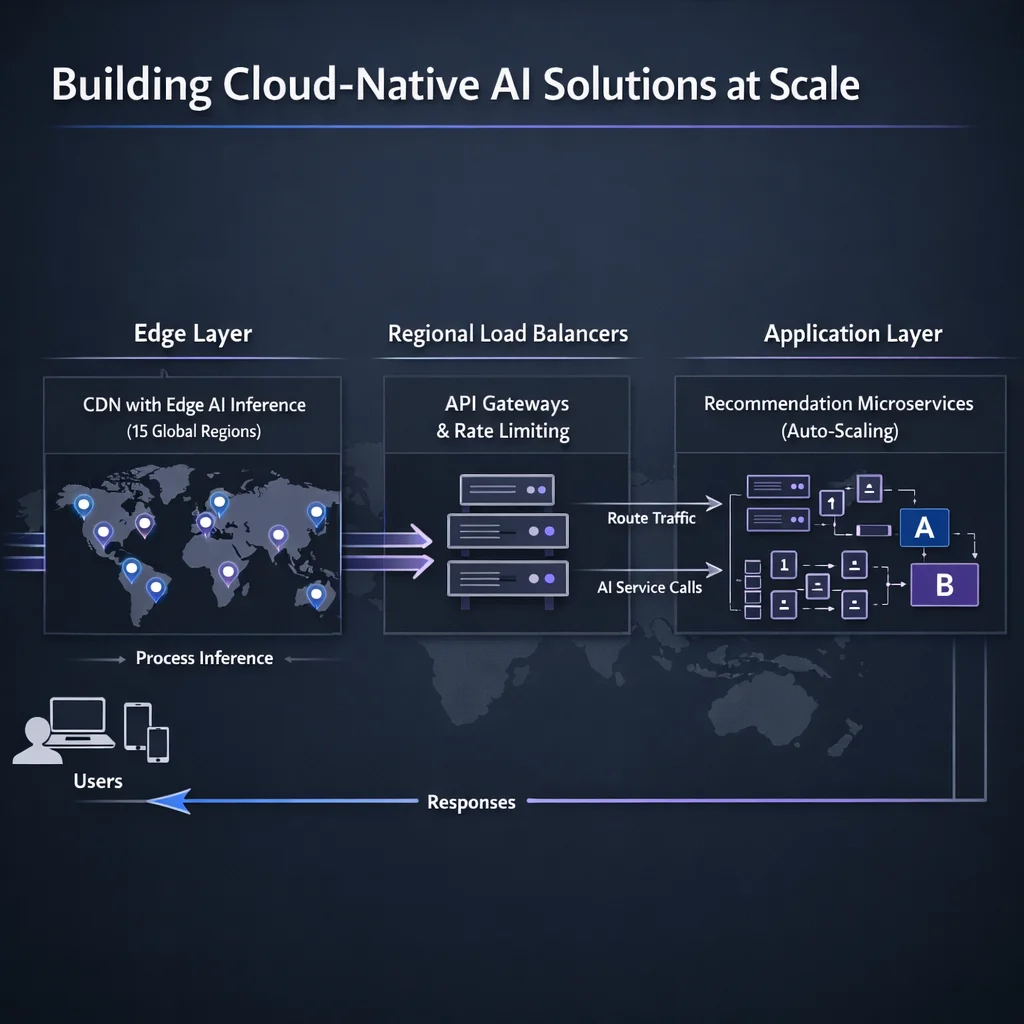Performance Results:
Requirements:
Security-First Architecture:
# Healthcare AI Security Configuration
apiVersion: v1
kind: Namespace
metadata:
name: healthcare-ai
labels:
compliance: hipaa
encryption: requiredCompliance Results:
Edge AI Integration:
class EdgeAIManager:
def __init__(self):
self.edge_nodes = self.discover_edge_nodes()
def deploy_lightweight_models(self):
Deploy optimized models to edge locations
for edge_node in self.edge_nodes:
optimized_model = self.create_edge_optimized_model(
base_model=self.production_model,
constraints=edge_node.resource_limits
)
self.deploy_to_edge(optimized_model, edge_node)
def implement_federated_learning(self):
Enable privacy-preserving distributed learning
federated_config = {
aggregation_strategy: FedAvg,
client_selection: random,
rounds: 100,
min_clients: 10,
privacy_budget: 1.0 # Differential privacy
}
return self.start_federated_training(federated_config)Cloud-native AI represents more than just a technological evolution—its a fundamental shift in how we build, deploy, and scale intelligent systems. Organizations that master cloud-native AI principles will be positioned to:
The key to success lies in embracing cloud-native principles while understanding the unique requirements of AI workloads. Start with solid foundations, implement robust monitoring and security, and continuously optimize for performance and cost.
This article is a live example of the AI-enabled content workflow we build for clients.
| Stage | Who | What |
|---|---|---|
| Research | Claude Opus 4.5 | Analyzed current industry data, studies, and expert sources |
| Curation | Tom Hundley | Directed focus, validated relevance, ensured strategic alignment |
| Drafting | Claude Opus 4.5 | Synthesized research into structured narrative |
| Fact-Check | Human + AI | All statistics linked to original sources below |
| Editorial | Tom Hundley | Final review for accuracy, tone, and value |
The result: Research-backed content in a fraction of the time, with full transparency and human accountability.
Were an AI enablement company. It would be strange if we didnt use AI to create content. But more importantly, we believe the future of professional content isnt AI vs. Human—its AI amplifying human expertise.
Every article we publish demonstrates the same workflow we help clients implement: AI handles the heavy lifting of research and drafting, humans provide direction, judgment, and accountability.
Want to build this capability for your team? Lets talk about AI enablement →
Discover more content: