
Implementing ethical AI practices that drive trust, compliance, and sustainable growth
As artificial intelligence becomes ubiquitous in business operations, the question isnt whether to implement AI ethics—its how to build robust governance frameworks that ensure AI systems are fair, transparent, and aligned with human values. Organizations that proactively address AI ethics dont just mitigate risks; they build competitive advantages through increased stakeholder trust and regulatory compliance.
This comprehensive guide provides practical frameworks for implementing AI ethics and governance, ensuring your AI initiatives create positive impact while minimizing potential harms.
The development of AI is not just a technological revolution; its a responsibility revolution. Every algorithm we deploy shapes the world we live in. - Fei-Fei Li, Stanford AI Lab
Risk Mitigation Benefits:
Competitive Advantages:
Algorithmic Bias and Fairness:
⚖️ Common Bias Types in Business AI
Our comprehensive TRUST framework provides a structured approach to ethical AI implementation:
Explainable AI Implementation:
import shap
import lime
from sklearn.ensemble import RandomForestClassifier
class ExplainableAISystem:
def __init__(self, model):
self.model = model
self.explainer = shap.TreeExplainer(model)
def explain_prediction(self, instance, explanation_type=shap):
Provide interpretable explanations for AI decisions
if explanation_type == shap:
shap_values = self.explainer.shap_values(instance)
explanation = {
prediction: self.model.predict([instance])[0],
confidence: self.model.predict_proba([instance]).max(),
feature_importance: dict(zip(
self.feature_names,
shap_values[0]
)),
explanation_type: SHAP values,
interpretation: self.generate_natural_language_explanation(
shap_values[0]
)
}
elif explanation_type == lime:
lime_explainer = lime.lime_classifier.LimeClassifierExplainer(
self.training_data,
feature_names=self.feature_names
)
explanation = lime_explainer.explain_instance(
instance,
self.model.predict_proba
)
return explanation
def generate_natural_language_explanation(self, shap_values):
Convert SHAP values to human-readable explanations
top_features = sorted(
zip(self.feature_names, shap_values),
key=lambda x: abs(x[1]),
reverse=True
)[:3]
explanation = This prediction was primarily influenced by:
for feature, impact in top_features:
direction = increased if impact 0 else decreased
explanation += f{feature} ({direction} likelihood),
return explanation.rstrip(, )Adversarial Testing Framework:
import numpy as np
from sklearn.metrics import accuracy_score
from adversarial_robustness_toolbox.attacks.evasion import FastGradientMethod
class AIRobustnessTester:
def __init__(self, model, test_data):
self.model = model
self.test_data = test_data
def test_adversarial_robustness(self, epsilon_values=[0.1, 0.2, 0.3]):
Test model robustness against adversarial attacks
robustness_results = {}
for epsilon in epsilon_values:
# Create adversarial examples
attack = FastGradientMethod(
estimator=self.model,
eps=epsilon
)
adversarial_examples = attack.generate(self.test_data.values)
# Evaluate performance on adversarial examples
clean_predictions = self.model.predict(self.test_data.values)
adversarial_predictions = self.model.predict(adversarial_examples)
robustness_score = accuracy_score(
clean_predictions,
adversarial_predictions
)
robustness_results[epsilon] = {
robustness_score: robustness_score,
performance_degradation: 1 - robustness_score,
recommendation: self.get_robustness_recommendation(
robustness_score
)
}
return robustness_results
def test_data_drift_detection(self, new_data):
Detect distribution shifts in input data
from scipy.stats import ks_2samp
drift_results = {}
for feature in self.test_data.columns:
statistic, p_value = ks_2samp(
self.test_data[feature],
new_data[feature]
)
drift_detected = p_value 0.05
drift_results[feature] = {
drift_detected: drift_detected,
p_value: p_value,
severity: High if p_value 0.01 else Medium if p_value 0.05 else Low
}
return drift_resultsFairness Assessment Tools:
from aif360.datasets import StandardDataset
from aif360.metrics import BinaryLabelDatasetMetric, ClassificationMetric
from aif360.algorithms.preprocessing import Reweighing
class FairnessAuditor:
def __init__(self, dataset, protected_attribute, favorable_label):
self.dataset = dataset
self.protected_attribute = protected_attribute
self.favorable_label = favorable_label
def assess_dataset_fairness(self):
Assess bias in training dataset
dataset_metric = BinaryLabelDatasetMetric(
self.dataset,
unprivileged_groups=[{self.protected_attribute: 0}],
privileged_groups=[{self.protected_attribute: 1}]
)
fairness_metrics = {
demographic_parity_difference: dataset_metric.mean_difference(),
disparate_impact: dataset_metric.disparate_impact(),
statistical_parity_difference: dataset_metric.statistical_parity_difference(),
consistency: dataset_metric.consistency()
}
return fairness_metrics
def assess_model_fairness(self, model_predictions):
Assess fairness of model predictions
classified_dataset = self.dataset.copy()
classified_dataset.labels = model_predictions
classification_metric = ClassificationMetric(
self.dataset,
classified_dataset,
unprivileged_groups=[{self.protected_attribute: 0}],
privileged_groups=[{self.protected_attribute: 1}]
)
model_fairness = {
equalized_odds_difference: classification_metric.equalized_odds_difference(),
average_odds_difference: classification_metric.average_odds_difference(),
theil_index: classification_metric.theil_index(),
false_positive_rate_difference: classification_metric.false_positive_rate_difference(),
false_negative_rate_difference: classification_metric.false_negative_rate_difference()
}
return model_fairness
def mitigate_bias(self, mitigation_method=reweighing):
Apply bias mitigation techniques
if mitigation_method == reweighing:
reweighing = Reweighing(
unprivileged_groups=[{self.protected_attribute: 0}],
privileged_groups=[{self.protected_attribute: 1}]
)
mitigated_dataset = reweighing.fit_transform(self.dataset)
return mitigated_datasetPrivacy-Preserving AI Techniques:
import numpy as np
from opacus import PrivacyEngine
import torch
import torch.nn as nn
class PrivacyPreservingAI:
def __init__(self, model, privacy_budget=1.0):
self.model = model
self.privacy_budget = privacy_budget
self.privacy_engine = PrivacyEngine()
def implement_differential_privacy(self, dataloader, optimizer):
Implement differential privacy during training
# Attach privacy engine to model and optimizer
self.model, optimizer, dataloader = self.privacy_engine.make_private(
module=self.model,
optimizer=optimizer,
data_loader=dataloader,
noise_multiplier=1.1,
max_grad_norm=1.0
)
return self.model, optimizer, dataloader
def federated_learning_setup(self, client_data):
Set up federated learning for privacy-preserving training
federated_config = {
num_clients: len(client_data),
local_epochs: 5,
aggregation_rounds: 100,
client_sampling_rate: 0.1,
secure_aggregation: True,
differential_privacy: {
enabled: True,
noise_multiplier: 1.0,
clipping_norm: 1.0
}
}
return federated_config
def homomorphic_encryption_inference(self, encrypted_input):
Perform inference on encrypted data
try:
from tenseal import context, ckks_vector
# Create CKKS context for homomorphic encryption
context = ts.context(
ts.SCHEME_TYPE.CKKS,
poly_modulus_degree=8192,
coeff_mod_bit_sizes=[60, 40, 40, 60]
)
context.generate_galois_keys()
context.global_scale = 2**40
# Encrypt input data
encrypted_vector = ckks_vector(context, encrypted_input)
# Perform encrypted computation
encrypted_result = self.encrypted_model_inference(encrypted_vector)
# Return encrypted result (client decrypts)
return encrypted_result
except ImportError:
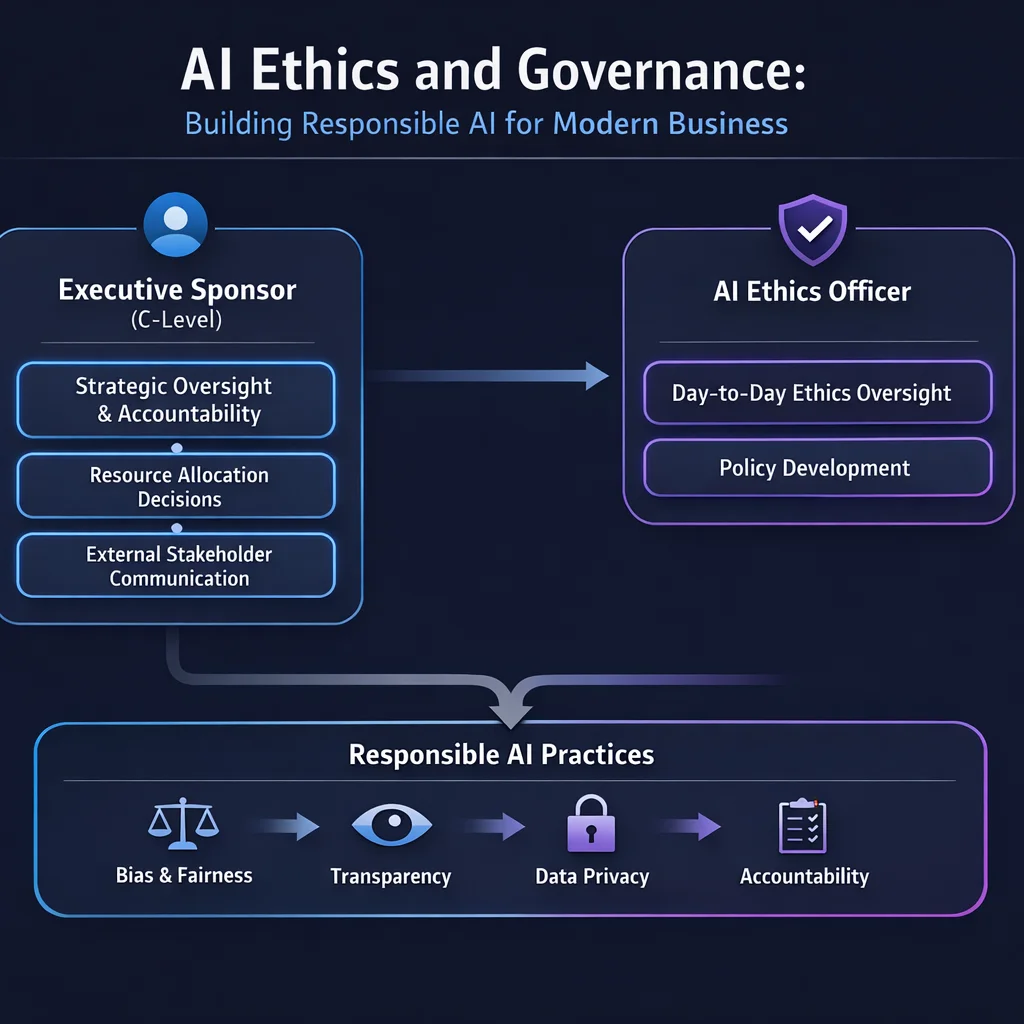
return Homomorphic encryption library not availableAI Governance Committee Structure:
🏛️ AI Ethics Committee Structure
GDPR and Fair Credit Reporting Act Compliance:
class FinancialAICompliance:
def __init__(self):
self.gdpr_requirements = self.load_gdpr_requirements()
self.fcra_requirements = self.load_fcra_requirements()
def implement_right_to_explanation(self, decision_id):
Provide detailed explanation for financial AI decisions
decision_record = self.get_decision_record(decision_id)
explanation = {
decision_summary: {
outcome: decision_record[prediction],
confidence: decision_record[confidence],
primary_factors: decision_record[top_factors][:5]
},
detailed_analysis: {
positive_factors: [f for f in decision_record[factors] if f[impact] 0],
negative_factors: [f for f in decision_record[factors] if f[impact] 0],
neutral_factors: [f for f in decision_record[factors] if f[impact] == 0]
},
regulatory_compliance: {
adverse_action_notice: self.generate_adverse_action_notice(decision_record),
appeal_process: self.get_appeal_process_info(),
data_sources: decision_record[data_sources],
credit_factors: self.extract_credit_factors(decision_record)
},
fairness_assessment: {
protected_class_impact: self.assess_protected_class_impact(decision_record),
disparate_impact_test: self.run_disparate_impact_test(decision_record),
bias_mitigation_applied: decision_record[bias_mitigation_methods]
}
}
return explanationHealthcare AI Ethics Implementation:
class HealthcareAIEthics:
def __init__(self):
self.hipaa_safeguards = self.initialize_hipaa_safeguards()
self.medical_ethics_framework = self.load_medical_ethics_framework()
def implement_clinical_decision_support_ethics(self):
Ethical framework for clinical decision support systems
ethical_guidelines = {
beneficence: {
patient_benefit_optimization: True,
harm_minimization: True,
outcome_improvement_tracking: True
},
autonomy: {
physician_override_capability: True,
patient_consent_for_ai: True,
treatment_option_transparency: True
},
justice: {
equitable_access: True,
bias_monitoring: True,
resource_allocation_fairness: True
},
non_maleficence: {
safety_monitoring: True,
adverse_event_tracking: True,
error_prevention_systems: True
}
}
return ethical_guidelinesWeek 1-2: Assessment and Planning
Week 3-4: Policy Development
Week 5-6: Technical Implementation
Week 7-8: Process Integration
Week 9-10: Testing and Validation
Week 11-12: Launch and Optimization
Regulatory Evolution:
Technical Advancements:
Stakeholder Expectations:
AI ethics isnt just about compliance—its about building sustainable competitive advantages through trust, transparency, and responsibility. Organizations that proactively implement robust AI ethics frameworks will:
The future belongs to organizations that can harness AIs power while maintaining human values and ethical principles. Start your ethics journey today—your stakeholders, your business, and society will benefit.
This article is a live example of the AI-enabled content workflow we build for clients.
| Stage | Who | What |
|---|---|---|
| Research | Claude Opus 4.5 | Analyzed current industry data, studies, and expert sources |
| Curation | Tom Hundley | Directed focus, validated relevance, ensured strategic alignment |
| Drafting | Claude Opus 4.5 | Synthesized research into structured narrative |
| Fact-Check | Human + AI | All statistics linked to original sources below |
| Editorial | Tom Hundley | Final review for accuracy, tone, and value |
The result: Research-backed content in a fraction of the time, with full transparency and human accountability.
Were an AI enablement company. It would be strange if we didnt use AI to create content. But more importantly, we believe the future of professional content isnt AI vs. Human—its AI amplifying human expertise.
Every article we publish demonstrates the same workflow we help clients implement: AI handles the heavy lifting of research and drafting, humans provide direction, judgment, and accountability.
Want to build this capability for your team? Lets talk about AI enablement ���
Discover more content: