
Every CTO planning AI initiatives eventually faces the same question: where do we run these workloads? The GPU compute requirements for modern AI are substantial, and the decisions you make about infrastructure will determine both your costs and your capability ceiling for years to come.
This isnt just about choosing a cloud provider. Its about architecting a compute strategy that balances cost, performance, compliance, and flexibility. Get it right, and AI becomes a competitive weapon. Get it wrong, and youll either overspend dramatically or find yourself constrained at exactly the wrong moment.
Lets start with hard numbers. According to GMI Clouds analysis, typical high-performance GPU instances range from about $2 to $15 per hour depending on the card, memory, and provider.
But heres where it gets interesting: an 8xH100 on-premise server might cost around $250,000, whereas renting the equivalent capacity in the cloud for three years could exceed $825,000. Thats a 3.3x cost multiplier for cloud over a three-year period.
Does that mean on-premise always wins? Not remotely. The calculation is far more nuanced.
Hyperscalers charge significant hidden costs for data egress, storage, and networking that can add 20-40% to the monthly bill. This transforms what looks like predictable cloud spending into a budgeting nightmare.
Common hidden cloud costs:
| Cost Category | Typical Impact |
|---|---|
| Data egress | $0.08-0.12 per GB |
| Premium storage (NVMe) | 2-3x standard rates |
| Cross-region transfer | Often overlooked in design |
| Idle capacity | GPUs billing when unused |
| Spot instance interruptions | Re-run costs + delays |
On the on-premise side, hidden costs include:
Despite the cost differential, cloud infrastructure wins in several scenarios:
If your AI compute needs spike during product launches, seasonal events, or experimental phases, cloud elasticity is worth the premium. Paying 3x per hour beats owning hardware that sits idle 70% of the time.
Cloud deployment happens in minutes. On-premise procurement takes months. For organizations racing to validate AI use cases, cloud removes a critical bottleneck.
If you need inference endpoints close to users worldwide, cloud providers global footprint is essentially impossible to replicate. Latency-sensitive applications—real-time recommendations, conversational AI—benefit enormously.
Managing GPU clusters requires specialized skills. If your team doesnt have (and cant hire) the expertise, cloud providers managed services reduce operational burden.
Healthcare (HIPAA), finance (SOC 2, PCI DSS), and government (FedRAMP) often mandate on-premise or private cloud. On-premise infrastructure provides organizations with direct, unambiguous control over their data, simplifying audits and removing the complexities of the clouds shared responsibility model.
If youre running inference 24/7 at scale, the math favors ownership. The $250K server that costs $825K in cloud over three years looks very different when utilization is consistently above 60%.
Training runs that consume thousands of GPU-hours per experiment can burn through cloud budgets rapidly. Organizations doing significant model development often find on-premise training clusters pay for themselves within 12-18 months.
When your training data is measured in petabytes, moving it to the cloud becomes prohibitively expensive and slow. Sometimes the compute has to go where the data lives.
The most effective strategy is often a hybrid one, where a foundational on-premise GPU cluster is augmented by the ability to burst into the cloud when demand spikes.
This approach allows organizations to:
A typical hybrid architecture:
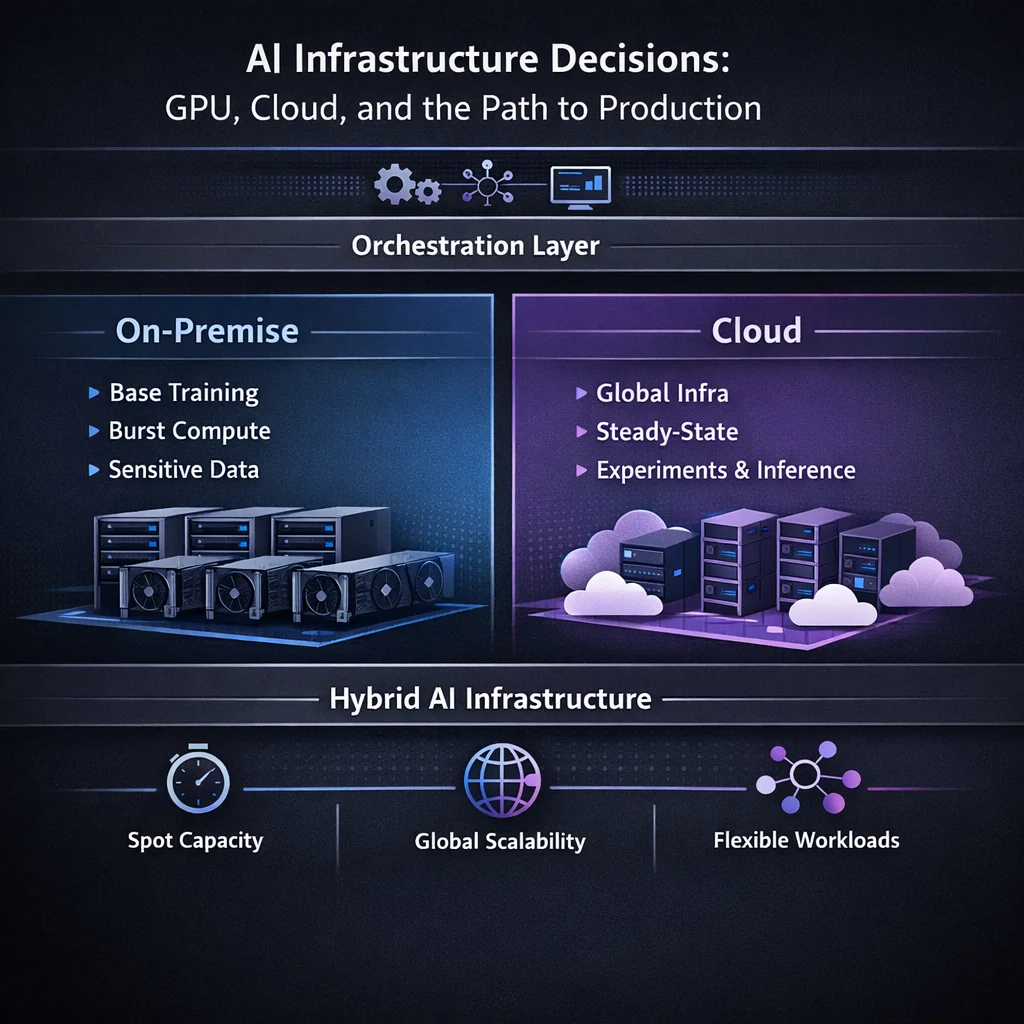
Not all clouds are created equal for AI workloads:
Specialized platforms like GMI Cloud offer NVIDIA H100 GPUs starting at rates as low as $2.10 per hour, which is often significantly cheaper than hyperscalers.
New platforms like ScaleOps are delivering major efficiency gains for early adopters, reducing GPU costs by between 50% and 70% for self-hosted enterprise LLMs.
Organizations analyzing economic alignment, workload requirements, and organizational capabilities through comprehensive TCO modeling position AI infrastructure as a competitive enabler rather than a commoditized cost center.
Categorize your AI workloads:
| Workload Type | Characteristics | Typical Best Fit |
|---|---|---|
| Experimentation | Variable, short bursts | Cloud (spot) |
| Model training | Intensive, periodic | Hybrid or On-prem |
| Development inference | Light, continuous | Cloud |
| Production inference | Heavy, continuous | On-prem or Hybrid |
| Edge inference | Distributed, latency-critical | Edge + Cloud |
Build a true 3-year TCO model that includes:
On-Premise:
Cloud:
Answer these questions:
The AI infrastructure landscape is evolving rapidly. GPU availability is improving, specialized providers are maturing, and hybrid orchestration tools are becoming more sophisticated. The decisions you make today dont have to be permanent—but they should be intentional.
The winners wont necessarily be those who spend the most on infrastructure. Theyll be the organizations that match their infrastructure strategy to their actual workload patterns, compliance requirements, and strategic objectives.
Cloud vs. on-premise isnt a religious debate. Its an optimization problem. And like all optimization problems, the answer depends entirely on your constraints and objectives.
div class=ai-collaboration-card
This article is a live example of the AI-enabled content workflow we build for clients.
| Stage | Who | What |
|---|---|---|
| Research | Claude Opus 4.5 | Analyzed current industry data, studies, and expert sources |
| Curation | Tom Hundley | Directed focus, validated relevance, ensured strategic alignment |
| Drafting | Claude Opus 4.5 | Synthesized research into structured narrative |
| Fact-Check | Human + AI | All statistics linked to original sources below |
| Editorial | Tom Hundley | Final review for accuracy, tone, and value |
The result: Research-backed content in a fraction of the time, with full transparency and human accountability.
/div
Were an AI enablement company. It would be strange if we didnt use AI to create content. But more importantly, we believe the future of professional content isnt AI vs. Human—its AI amplifying human expertise.
Every article we publish demonstrates the same workflow we help clients implement: AI handles the heavy lifting of research and drafting, humans provide direction, judgment, and accountability.
Want to build this capability for your team? Lets talk about AI enablement →
Discover more content: