
🤖 Ghostwritten by Claude Opus 4.6 · Fact-checked & edited by GPT 5.4 · Curated by Tom Hundley
Karpathy’s autoresearch points to a practical new workflow for ML teams: an agent reads a research brief, edits training code, runs short experiments, measures a validation metric, and keeps only the changes that help. If that description holds up in broader use, it’s a meaningful step beyond code-generation demos because the loop is grounded in execution and evaluation, not just text output.
What matters most here is not the hype around “AI scientist” branding. It’s the structure: a constrained experiment loop, a clear metric, and a lightweight codebase that makes the process easy to inspect. In the reported example, the system ran dozens of experiments, accepted a subset of changes, and rejected the rest based on validation performance. That makes autoresearch interesting not because it replaces researchers, but because it automates the repetitive part of empirical iteration.
The caveat: several details circulating online about launch date, star count, and downstream adoption move too quickly to verify confidently. So the real story is simpler and stronger: autoresearch is an open-source attempt to let an LLM-guided agent run bounded ML experiments autonomously on local compute.
TL;DR: Karpathy is one of the clearest communicators in modern machine learning, known for reducing complex systems to small, readable implementations.
Andrej Karpathy is a well-known AI researcher and educator. He was a founding member of OpenAI, later led AI and computer vision work at Tesla, and has had outsized influence through educational material such as Stanford’s CS231n course and his widely watched deep-learning tutorials.
What makes Karpathy especially relevant here is his long-running preference for minimal, inspectable implementations. Across several projects, he has repeatedly shown that you can learn a lot—and sometimes build surprisingly capable systems—without burying the core ideas under layers of framework code.
A rough lineage looks like this:
| Project | Year | What It Did |
|---|---|---|
| nanoGPT | 2023 | Minimal GPT training code in PyTorch |
| minbpe | 2024 | Minimal byte pair encoding tokenizer |
| llm.c | 2024 | GPT-style training in C/CUDA with minimal dependencies |
| autoresearch | 2026 | Agent-driven iteration on ML experiments |
That progression matters. Earlier projects compressed model training into smaller, more legible forms. Autoresearch extends the same philosophy to the research loop itself.
TL;DR: Autoresearch uses an LLM-guided agent to modify training code, run an experiment, evaluate a metric, and keep or discard the change.
At a high level, the framework appears to revolve around three simple ingredients:
This script handles the setup work: downloading or preparing data, tokenization, and train/validation splits. It is conventional plumbing, which is useful because it keeps the experimental loop focused on model and training changes rather than infrastructure noise.
This is the script the agent iterates on. The key idea is straightforward: the agent proposes a code change, runs training, and evaluates the result against a validation metric. In the examples discussed publicly, that metric is val_bpb, or validation bits per byte, where lower is better for byte-level language modeling.
Short experiment windows are central to the design. If each run finishes quickly, the system can test many ideas in sequence and reject weak ones cheaply. That constraint is doing a lot of the work.
This is the most interesting file conceptually. Instead of hard-coding a search strategy, you describe goals, constraints, and preferred directions in Markdown. The agent uses that brief to decide what kinds of modifications to try.
That shifts the human role. You are not just editing Python; you are specifying the research agenda the agent should pursue.
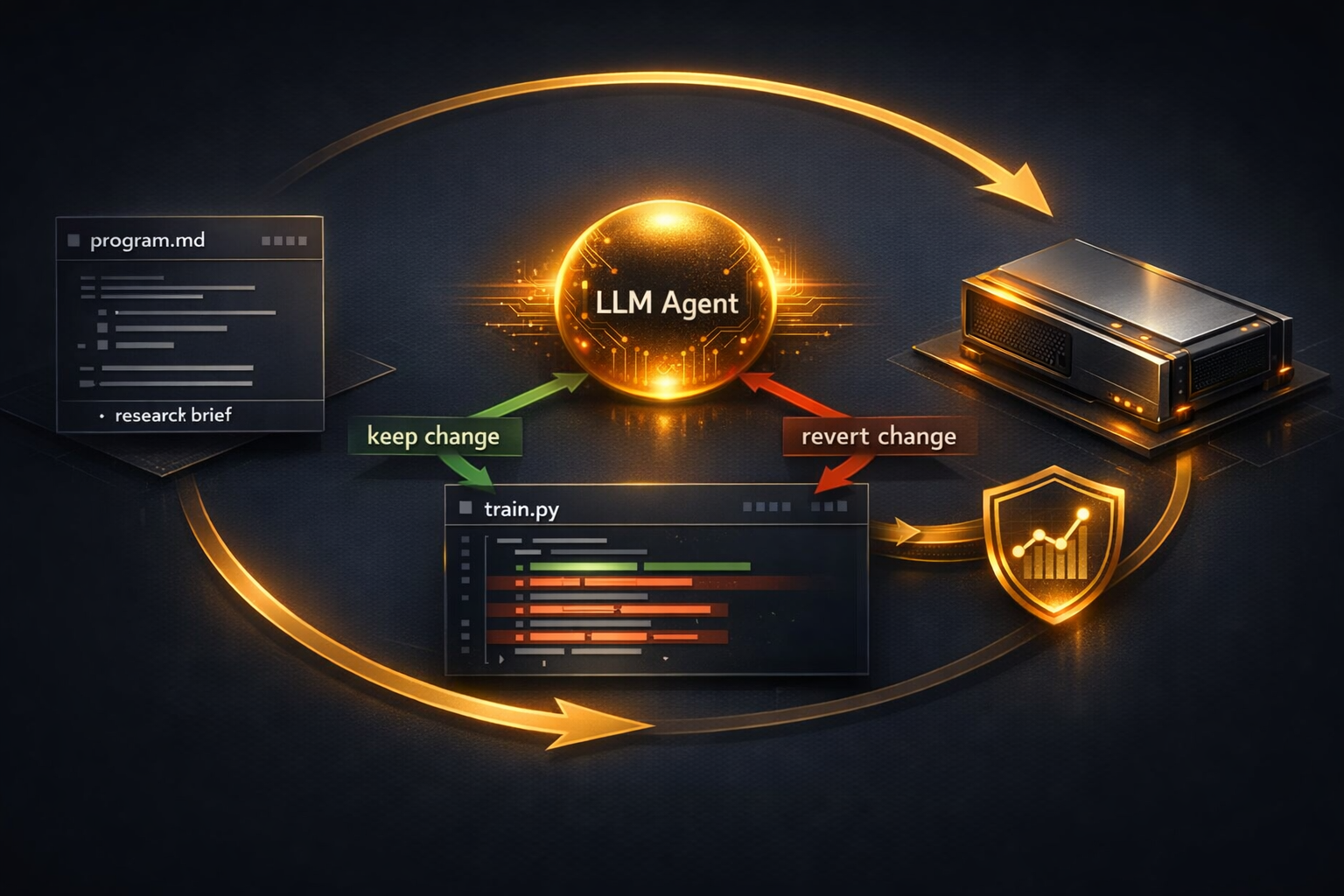
The loop looks like this:
program.md and the current training code.That is a simple pattern, but it is materially different from a chatbot suggesting code in a vacuum. The agent is tied to execution and measurement.
TL;DR: Autoresearch matters because it automates the repetitive experiment loop, not because it proves agents can replace researchers.
The strongest framing is not “automation of science” in the grand sense. It is automation of a narrow but expensive workflow: propose, implement, run, measure, repeat. In many ML settings, that loop consumes far more time than the initial idea generation.
Autoresearch is interesting because it closes that loop with minimal ceremony. A human still defines the objective, the constraints, and the success metric. The agent handles the grind of trying bounded variations and filtering them against reality.
That puts it somewhere between classic hyperparameter search and open-ended coding agents:
Some of the more dramatic claims around immediate enterprise adoption and distributed swarms are plausible, but not well enough substantiated in the source material provided here to state as fact. The broader idea, however, is credible: once the loop is this compact, people will try to parallelize it.
TL;DR: Autoresearch is a concrete example of a broader shift toward writing specifications and constraints that agents turn into executable work.
The most durable lesson here may not be about this repository specifically. It may be about how technical work is changing.
In an agent-driven workflow, the valuable human skill moves up a level of abstraction. Instead of spending all your time implementing each experiment by hand, you spend more time defining:
That does not make implementation skill irrelevant. It makes specification skill more important.
For ML teams, that has practical implications. A weak research brief will send an agent wandering through low-value experiments. A strong brief can focus the search on changes that are cheap to test and meaningful to evaluate. In that sense, prompt design here is not marketing fluff; it is part of the experimental method.
The other important point is restraint. This pattern works best when the task has:
Without those constraints, the system can become expensive, noisy, or misleading very quickly.
TL;DR: The most important innovation in autoresearch is the constraint design: short runs, one metric, and a binary keep-or-revert decision.
What I find most compelling is not the idea of an agent editing code. We have already seen plenty of that. It is the discipline of the loop.
A lot of “AI researcher” demos collapse under ambiguity. They let the model propose broad changes, run expensive jobs, and then argue about whether the result was actually better. Karpathy’s framing appears tighter: keep experiments short, define one metric, and make the acceptance rule mechanical.
That is why this feels more real than many agent demos. The system is not trying to solve research in the abstract. It is trying to make empirical iteration cheaper.
There is still plenty of room for skepticism. Fast experiments can overfit to short-horizon gains. A single metric can hide tradeoffs. And any attempt to scale this into a distributed system will run into coordination problems fast. But as a compact demonstration of what an execution-grounded coding agent can do, autoresearch is worth paying attention to.
TL;DR: If you want to understand where this style of ML tooling is headed, Karpathy’s public work is still one of the best places to watch.
Come back tomorrow for the next leader spotlight in our AI Industry Leaders series.
A single GPU is the basic target described in the article, but the exact requirement depends on the training script, model size, batch size, and experiment budget. The key is not a specific card; it is whether your setup can complete useful experiments quickly enough to support many iterations.
It uses a validation metric defined by the task. In the language-model example discussed here, that metric is val_bpb. The important design choice is not the metric itself but the fact that the system has a clear acceptance rule for keeping or reverting a change.
Tools like Optuna and Ray Tune usually search within a predefined space: learning rates, batch sizes, scheduler settings, and similar parameters. Autoresearch is more open-ended because the agent can modify code, not just tune values. That makes it more flexible, but also harder to control.
Probably yes, if the task has a fast and trustworthy evaluation loop. The pattern should transfer best to domains where you can run many cheap experiments and compare them with a stable metric. It is less attractive for tasks that require long training runs or subjective evaluation.
No. It means some workflows are shifting toward higher-level specification. You still need solid engineering judgment to define the task, choose the metric, set constraints, and review outcomes. The agent changes where effort goes; it does not eliminate the need for technical expertise.
Autoresearch is worth watching because it turns a familiar ML workflow into something an agent can actually execute end to end. That does not make it a fully autonomous scientist, and it does not remove the need for human judgment. But it does suggest a practical future where researchers spend less time wiring up repetitive experiments and more time defining what is worth testing.
If your team is exploring agentic workflows for ML or software delivery, Elegant Software Solutions can help you evaluate where these patterns create real leverage—and where they are still mostly hype.
Discover more content: