
When retrieve-and-generate is not enough.
Throughout this series, we have built RAG systems with LangChain, LlamaIndex, Haystack, and various cloud platforms. All of them follow the same fundamental pattern: take a query, retrieve documents, stuff them into a prompt, generate an answer.
This pattern works remarkably well for straightforward knowledge retrieval. But it breaks down when:
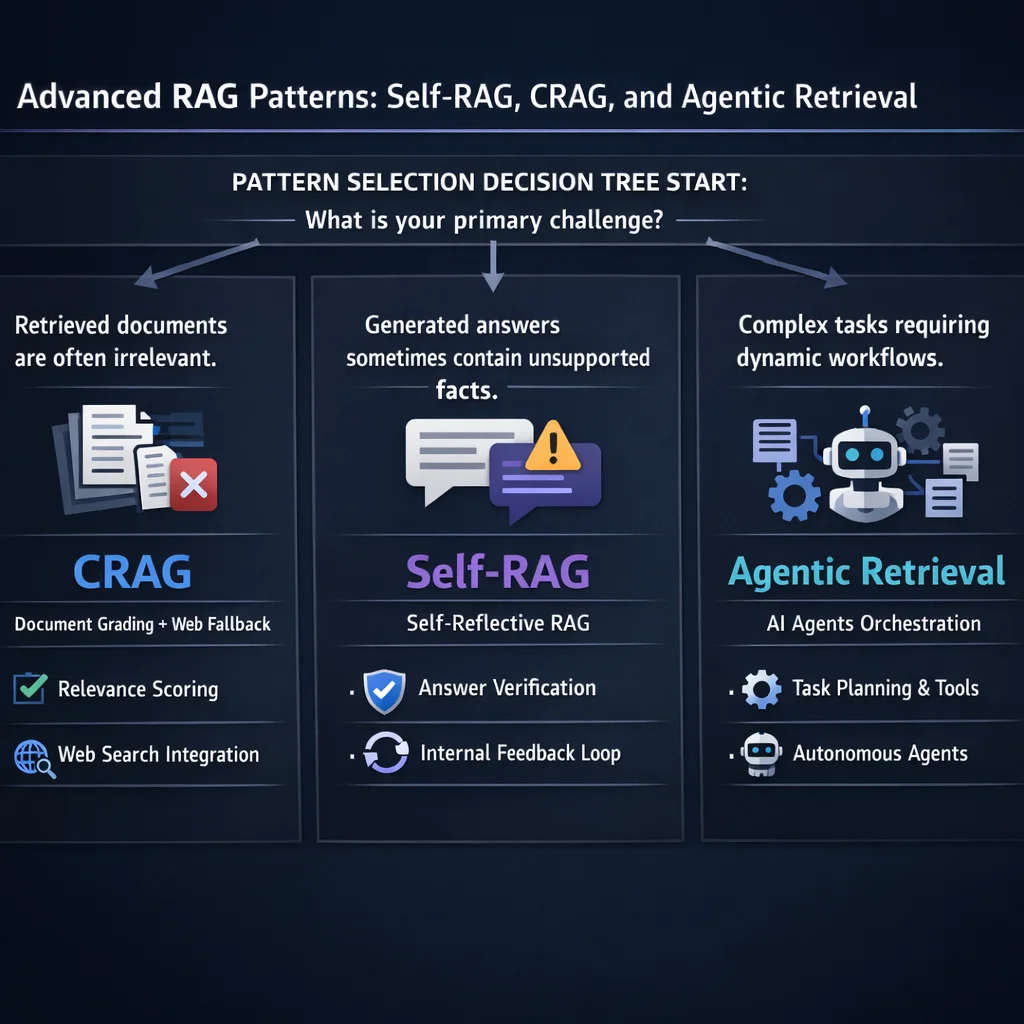
This article explores the advanced patterns that address these limitations: Self-RAG, Corrective RAG, agentic retrieval, multi-modal RAG, and Graph RAG. These are not theoretical concepts. They are production patterns deployed in systems where basic RAG falls short.
The standard RAG pipeline assumes a clean, linear flow:

This works when three assumptions hold:
In production, these assumptions frequently fail.
Problem 1: Retrieval quality is invisible. The system returns the k most similar documents, but "most similar" does not mean "relevant." Embedding models can confidently retrieve tangentially related content, and the generation step has no mechanism to detect this.
Problem 2: Single-pass retrieval is insufficient. Complex questions often require information scattered across multiple document types. A question like "How did our refund policy change after the 2023 lawsuit?" requires retrieving both the current policy and historical legal documents. A single embedding-based retrieval rarely surfaces both.
Problem 3: No feedback loop. The system generates an answer and returns it. There is no verification that the answer actually addresses the question, no check that the cited context supports the claims, no mechanism to try again if the first attempt fails.
Problem 4: Garbage in, garbage out. If the knowledge base contains outdated, conflicting, or incomplete information, the LLM will faithfully synthesize a response from that flawed context. The model has no way to know it should supplement with external knowledge.
Advanced RAG patterns address these problems by adding intelligence to the retrieval and generation loop:

Before diving into complex patterns, a calibration: most RAG applications do not need these techniques.
Use basic RAG when:
Consider advanced patterns when:
The advanced patterns in this article add latency, complexity, and cost. Use them when the business requirement justifies the investment.
Self-RAG introduces a simple but powerful concept: teach the model to critique its own retrieval and generation decisions.
The Self-RAG framework, introduced by researchers at Carnegie Mellon and IBM Research in 2023, augments the language model with special tokens that control its behavior:

The key insight: rather than always retrieving (which adds latency and can introduce noise) or never retrieving (which limits the model to its training data), Self-RAG learns when retrieval is necessary and whether the retrieved content actually helps.
LangGraph provides the control flow primitives needed to implement Self-RAG. Here is the core structure:
"""
Self-RAG implementation with LangGraph.
Key nodes: decide_retrieval -> retrieve -> grade -> generate -> check_hallucination
"""
from typing import TypedDict, List, Literal
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
import json
class SelfRAGState(TypedDict):
query: str
documents: List[Document]
generation: str
retrieval_decision: Literal["retrieve", "generate"]
support_score: float
iteration: int
llm = ChatOpenAI(model="gpt-4o", temperature=0)
def decide_retrieval(state: SelfRAGState) -> SelfRAGState:
"""Determine if retrieval is necessary for this query."""
# LLM decides: retrieve for private/specific data, generate for general knowledge
# Returns: {..."retrieval_decision": "retrieve" | "generate"}
pass
def grade_documents(state: SelfRAGState) -> SelfRAGState:
"""Grade retrieved documents for relevance (0-1 scale)."""
# Filters documents with relevance > 0.5
pass
def check_hallucination(state: SelfRAGState) -> SelfRAGState:
"""Verify generated answer is supported by documents."""
# Returns support_score: 0-1, unsupported_claims list
pass
def should_regenerate(state: SelfRAGState) -> Literal["regenerate", "finalize"]:
"""Regenerate if support_score < 0.7 and iteration < 3."""
if state["support_score"] < 0.7 and state["iteration"] < 3:
return "regenerate"
return "finalize"
def build_self_rag_graph():
workflow = StateGraph(SelfRAGState)
workflow.add_node("decide_retrieval", decide_retrieval)
workflow.add_node("retrieve", retrieve_documents)
workflow.add_node("grade", grade_documents)
workflow.add_node("generate", generate_answer)
workflow.add_node("check_hallucination", check_hallucination)
workflow.add_node("regenerate", regenerate_with_feedback)
workflow.add_node("finalize", finalize_answer)
workflow.set_entry_point("decide_retrieval")
# Conditional: retrieve or generate directly
workflow.add_conditional_edges(
"decide_retrieval",
lambda s: s["retrieval_decision"],
{"retrieve": "retrieve", "generate": "generate"}
)
workflow.add_edge("retrieve", "grade")
workflow.add_edge("grade", "generate")
workflow.add_edge("generate", "check_hallucination")
# Conditional: regenerate or finalize based on hallucination check
workflow.add_conditional_edges(
"check_hallucination",
should_regenerate,
{"regenerate": "regenerate", "finalize": "finalize"}
)
workflow.add_edge("regenerate", "check_hallucination")
workflow.add_edge("finalize", END)
return workflow.compile()Retrieval tokens: The model learns to emit special tokens indicating whether retrieval is needed. This prevents unnecessary retrieval for queries the model can answer from parametric knowledge.
Relevance tokens: After retrieval, the model assesses whether each document is actually relevant. This creates a feedback signal that can improve retrieval over time.
Support tokens: During generation, the model tracks whether its claims are supported by the retrieved documents. Claims without support can be flagged or regenerated.
The refinement loop: When support scores are low, the system regenerates with explicit feedback about which claims lacked support. This iterative refinement typically converges in 1-3 iterations.
Self-RAG adds value in specific scenarios:
| Scenario | Self-RAG Benefit |
|---|---|
| Mixed query types (some need retrieval, some do not) | Retrieval decision saves latency on simple queries |
| High-stakes domains (legal, medical, financial) | Hallucination detection catches unsupported claims |
| Knowledge bases with varying quality | Relevance grading filters out noise |
| User-facing applications | Self-critique improves answer quality before delivery |
Skip Self-RAG when:
In production deployments, consider these optimizations:
Use smaller models for critique steps: The retrieval decision and hallucination check can often use GPT-4o-mini while reserving GPT-4o for final generation.
Set early termination thresholds: If the first generation has a support score >0.9, skip the refinement loop entirely.
Cache retrieval decisions: For similar queries, the retrieval decision often remains stable. Consider semantic caching.
Monitor iteration counts: If queries frequently require 3+ iterations, your retrieval or generation quality likely needs improvement upstream.
While Self-RAG focuses on the generation phase, Corrective RAG (CRAG) addresses a different problem: what happens when your knowledge base simply does not contain the answer?
CRAG, introduced in early 2024, adds a knowledge refinement step between retrieval and generation. Instead of blindly generating from whatever documents were retrieved, CRAG evaluates retrieval quality and takes corrective action:
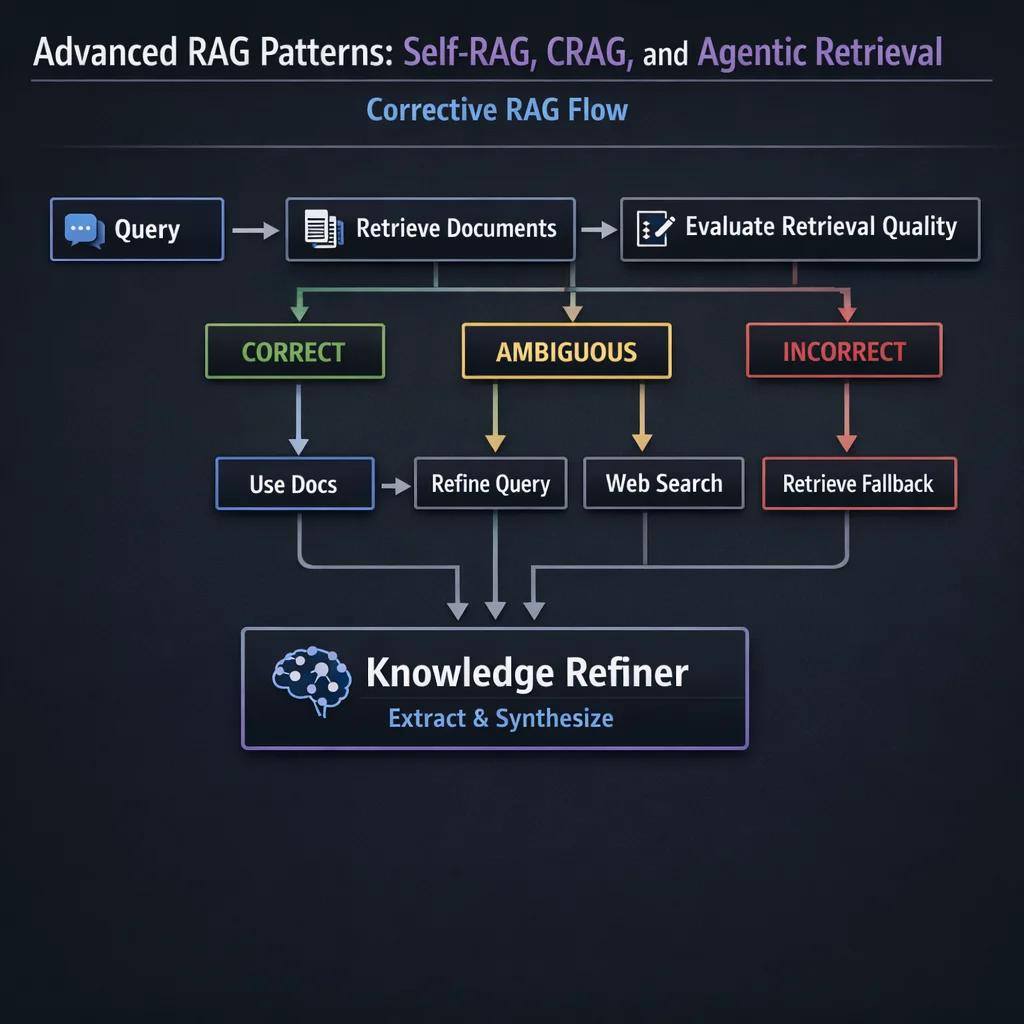
"""
Corrective RAG: Evaluate retrieval quality and take corrective action.
"""
from typing import TypedDict, List, Literal
from langgraph.graph import StateGraph, END
class CRAGState(TypedDict):
query: str
documents: List[Document]
retrieval_quality: Literal["correct", "ambiguous", "incorrect"]
refined_documents: List[Document]
web_results: List[Document]
final_context: List[Document]
def evaluate_retrieval(state: CRAGState) -> CRAGState:
"""
LLM classifies retrieval quality:
- correct: Documents contain the answer -> use as-is
- ambiguous: Partially relevant -> refine + supplement with web
- incorrect: Not helpful -> fall back to web search
"""
pass
def refine_documents(state: CRAGState) -> CRAGState:
"""Extract only relevant sentences from retrieved documents."""
# LLM extracts specific passages that address the query
pass
def web_search_fallback(state: CRAGState) -> CRAGState:
"""Search web when internal knowledge is insufficient."""
# Uses Tavily, Serper, or similar search API
pass
def combine_knowledge(state: CRAGState) -> CRAGState:
"""Merge internal and external sources based on quality."""
quality = state["retrieval_quality"]
if quality == "correct":
return {**state, "final_context": state["refined_documents"]}
elif quality == "ambiguous":
return {**state, "final_context": state["refined_documents"] + state["web_results"]}
else:
return {**state, "final_context": state["web_results"]}
def build_crag_graph():
workflow = StateGraph(CRAGState)
workflow.add_node("evaluate", evaluate_retrieval)
workflow.add_node("refine", refine_documents)
workflow.add_node("web_search", web_search_fallback)
workflow.add_node("combine", combine_knowledge)
workflow.add_node("generate", generate_answer)
workflow.set_entry_point("evaluate")
# Route based on quality assessment
workflow.add_conditional_edges(
"evaluate",
lambda s: {
"correct": "refine",
"ambiguous": "refine",
"incorrect": "web_search"
}[s["retrieval_quality"]]
)
workflow.add_conditional_edges(
"refine",
lambda s: "web_search" if s["retrieval_quality"] == "ambiguous" else "combine"
)
workflow.add_edge("web_search", "combine")
workflow.add_edge("combine", "generate")
workflow.add_edge("generate", END)
return workflow.compile()Retrieval evaluator: A lightweight classifier that determines if retrieved documents are sufficient. This avoids wasting LLM tokens on useless context.
Knowledge refinement: Even "correct" retrievals often contain noise. The refinement step extracts only the sentences that directly address the query.
Web search fallback: When internal knowledge is insufficient, CRAG automatically searches the web. This is crucial for questions about recent events or topics outside the knowledge base scope.
Source fusion: The system can combine internal and external sources, giving priority to authoritative internal documents while supplementing with web content.
These patterns solve different problems and can be combined:
| Problem | Pattern | Solution |
|---|---|---|
| Retrieved docs are irrelevant | CRAG | Evaluate before generating, fall back to web |
| Generated answer contains hallucinations | Self-RAG | Critique and regenerate |
| Knowledge base has gaps | CRAG | Supplement with web search |
| Some queries do not need retrieval | Self-RAG | Retrieval decision logic |
Combining the patterns: In production, many systems use both:
The web search fallback requires choosing a search provider. Common options:
| Provider | Pros | Cons |
|---|---|---|
| Tavily | Designed for AI, structured results | Paid, rate limits |
| Serper | Google results, reliable | Paid, may need scraping |
| Brave Search API | Good privacy, reasonable pricing | Smaller index than Google |
| SerpAPI | Multiple engines, structured | Higher cost at scale |
| Bing Search API | Azure integration, enterprise | Microsoft ecosystem lock-in |
For sensitive domains, consider whether web search is appropriate. Legal, medical, and financial applications may need to restrict sources to vetted knowledge bases only.
Agentic RAG treats retrieval as a tool that an agent can invoke as needed during multi-step reasoning. Rather than a fixed retrieve-then-generate pipeline, the agent decides when and what to retrieve based on its evolving understanding of the problem.
In agentic architectures, retrieval becomes one of several tools available to the agent:
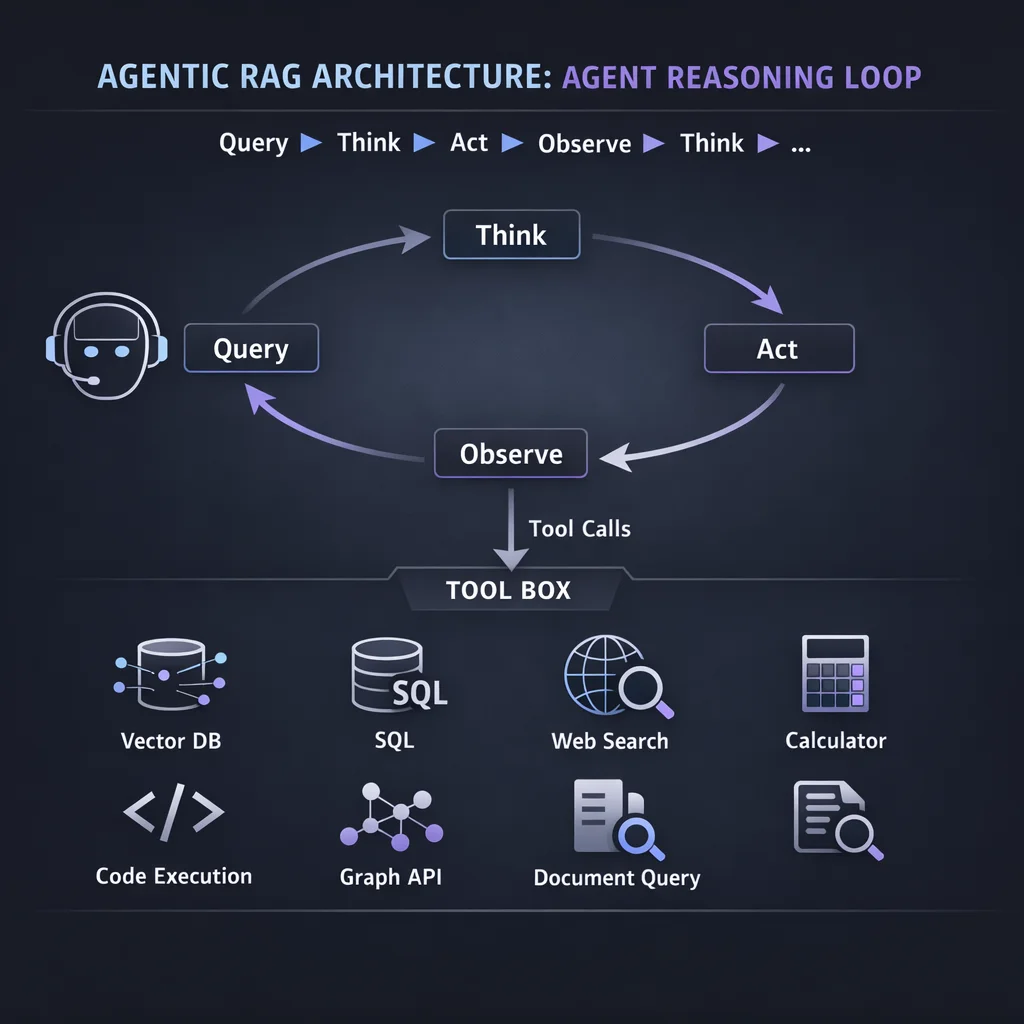
Complex questions often cannot be answered with a single retrieval. Agentic RAG decomposes queries into sub-questions:
"""
Agentic RAG with query decomposition and multi-step reasoning.
"""
from langchain_core.tools import tool
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
# Define retrieval tools
@tool
def search_knowledge_base(query: str) -> str:
"""Search internal knowledge base for company-specific information."""
pass
@tool
def search_web(query: str) -> str:
"""Search web for current events and external information."""
pass
@tool
def query_database(sql_description: str) -> str:
"""Query structured data from the database."""
pass
tools = [search_knowledge_base, search_web, query_database]
llm = ChatOpenAI(model="gpt-4o", temperature=0).bind_tools(tools)
def decompose_query(state: AgentState) -> AgentState:
"""Break complex query into 2-4 sub-questions."""
# LLM analyzes question complexity and returns sub-questions
# Example: "Compare Q3 vs Q4 sales" -> ["Get Q3 sales", "Get Q4 sales", "Compare"]
pass
def agent_reasoning(state: AgentState) -> AgentState:
"""ReAct loop: Think about current sub-question, choose tool, observe result."""
# Agent decides: which tool to call, or synthesize final answer
pass
def build_agentic_rag():
workflow = StateGraph(AgentState)
workflow.add_node("decompose", decompose_query)
workflow.add_node("agent", agent_reasoning)
workflow.add_node("tools", ToolNode(tools))
workflow.set_entry_point("decompose")
workflow.add_edge("decompose", "agent")
# ReAct loop: agent -> tools -> agent until no more tool calls
workflow.add_conditional_edges(
"agent",
lambda s: "tools" if s["messages"][-1].tool_calls else "end",
{"tools": "tools", "end": END}
)
workflow.add_edge("tools", "agent")
return workflow.compile()Not every query needs the full agentic treatment. Routers classify queries and dispatch them to appropriate handlers:
"""
Query routing: Simple queries get simple handlers; complex queries get agents.
"""
from pydantic import BaseModel, Field
from typing import Literal
class RouteQuery(BaseModel):
route: Literal["simple_rag", "multi_hop", "agentic", "no_retrieval"]
reasoning: str
def create_semantic_router():
"""LLM-based router that classifies queries by complexity."""
router_prompt = """Classify the query:
- simple_rag: Single document likely sufficient ("What is our vacation policy?")
- multi_hop: Multiple documents needed ("Compare 2023 and 2024 strategies")
- agentic: Reasoning/calculation required ("Which product line to discontinue?")
- no_retrieval: General knowledge ("What is the capital of France?")
"""
return ChatPromptTemplate.from_messages([
("system", router_prompt),
("human", "{query}")
]) | llm.with_structured_output(RouteQuery)
def route_and_execute(query: str):
route = create_semantic_router().invoke({"query": query})
handlers = {
"simple_rag": execute_simple_rag,
"multi_hop": execute_crag,
"agentic": execute_agentic_rag,
"no_retrieval": lambda q: llm.invoke(q).content
}
return handlers[route.route](query)Agentic RAG is the most powerful but also most complex pattern. Use it when:
Good candidates for agentic RAG:
Overkill for:
Limit tool diversity: Start with 3-5 focused tools. Too many options confuse the agent and slow decision-making.
Provide clear tool descriptions: The agent chooses tools based on descriptions. "Search internal docs" is vague; "Search company policies and HR documents" is actionable.
Set iteration limits: Agents can loop indefinitely. Set a maximum of 5-7 tool calls before forcing a final answer.
Include a "give up" path: If the agent cannot find information after reasonable effort, it should say so rather than hallucinate.
Log everything: Agentic systems are hard to debug. Log every tool call, every decision, every intermediate result.
Real-world knowledge bases contain more than text. PDFs have charts. Documentation includes diagrams. Product catalogs feature images. Multi-modal RAG extends retrieval to these non-text modalities.

CLIP Embeddings: CLIP (Contrastive Language-Image Pre-training) creates embeddings where images and text share the same vector space. You can retrieve images using text queries.
"""Multi-modal RAG with CLIP for images."""
from transformers import CLIPProcessor, CLIPModel
class MultiModalEmbedder:
def __init__(self):
self.clip = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def embed_image(self, image_path: str) -> list[float]:
"""Embed image into same vector space as text."""
image = Image.open(image_path)
inputs = self.processor(images=image, return_tensors="pt")
features = self.clip.get_image_features(**inputs)
return (features / features.norm()).squeeze().tolist()
def embed_text_for_image_search(self, text: str) -> list[float]:
"""Embed text query for cross-modal retrieval."""
inputs = self.processor(text=[text], return_tensors="pt", padding=True)
features = self.clip.get_text_features(**inputs)
return (features / features.norm()).squeeze().tolist()Vision Model Summarization: For complex images like charts, use GPT-4o to generate descriptions, then embed those descriptions:
def describe_image_for_embedding(image_path: str) -> str:
"""Use GPT-4o to generate searchable description of image."""
image_b64 = base64.b64encode(Path(image_path).read_bytes()).decode()
return ChatOpenAI(model="gpt-4o").invoke([HumanMessage(content=[
{"type": "text", "text": "Describe this image for a search index: content, data points, visible text."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_b64}"}}
])]).contentPDFs have structure beyond text. Modern multi-modal RAG preserves this:
"""PDF processing with layout understanding using Unstructured."""
from unstructured.partition.pdf import partition_pdf
from unstructured.chunking.title import chunk_by_title
def process_pdf_with_structure(pdf_path: str) -> List[Dict]:
# Vision-based layout detection
elements = partition_pdf(
filename=pdf_path,
strategy="hi_res", # Uses vision model
extract_images_in_pdf=True,
infer_table_structure=True,
)
# Chunk by structural elements (headers become chunk boundaries)
chunks = chunk_by_title(elements, max_characters=1500)
return [
{
"content": str(chunk),
"type": getattr(chunk, 'category', 'text'), # Table, Image, NarrativeText
"page": getattr(chunk.metadata, 'page_number', None)
}
for chunk in chunks
]ColPali embeds entire document pages as images, preserving layout directly:
class DocumentImageRetriever:
"""
Treats document pages as images for retrieval.
Advantages: Preserves layout, handles tables/figures naturally
Trade-offs: Higher storage, may miss fine-grained text matching
"""
def __init__(self, model_name: str = "vidore/colpali-v1.2"):
# Load ColPali vision-document model
pass
def embed_page_image(self, page_image: Image) -> list[float]:
"""Embed full page capturing both layout and text content."""
pass
def answer_with_page_context(self, query: str, pages: list[Image]) -> str:
"""Pass query + page images to GPT-4o/Claude for visual QA."""
pass| Approach | When to Use | Limitations |
|---|---|---|
| CLIP embeddings | Image-heavy catalogs, visual search | Limited text understanding |
| Vision model summaries | Charts, diagrams, infographics | Slow, expensive per image |
| PDF layout parsing | Structured documents, forms | Complex pipeline setup |
| ColPali page images | Mixed documents, quick setup | Higher storage, coarse retrieval |
| Hybrid (text + vision) | Production systems | Most complex to implement |
For most enterprise RAG systems, the recommended approach is:
Vector search finds similar content. Knowledge graphs find connected content. Graph RAG combines both for queries that require understanding relationships.
For a deep dive into knowledge graphs, see our article on Knowledge Graphs for AI: Beyond Vector Search. Here we focus on the integration with RAG.
Vector embeddings encode semantic meaning but lose explicit relationships:
Query: "Which projects are affected by the Q1 budget cut?"
Vector Search Results:
1. "Q1 Budget Planning Meeting Notes" - mentions budget
2. "Project Alpha Status Report" - mentions budget concerns
3. "Annual Financial Overview" - mentions Q1
Problem: These are semantically related, but vector search cannot trace
the actual relationship: Budget Decision → affects → Project List → contains → Specific Projects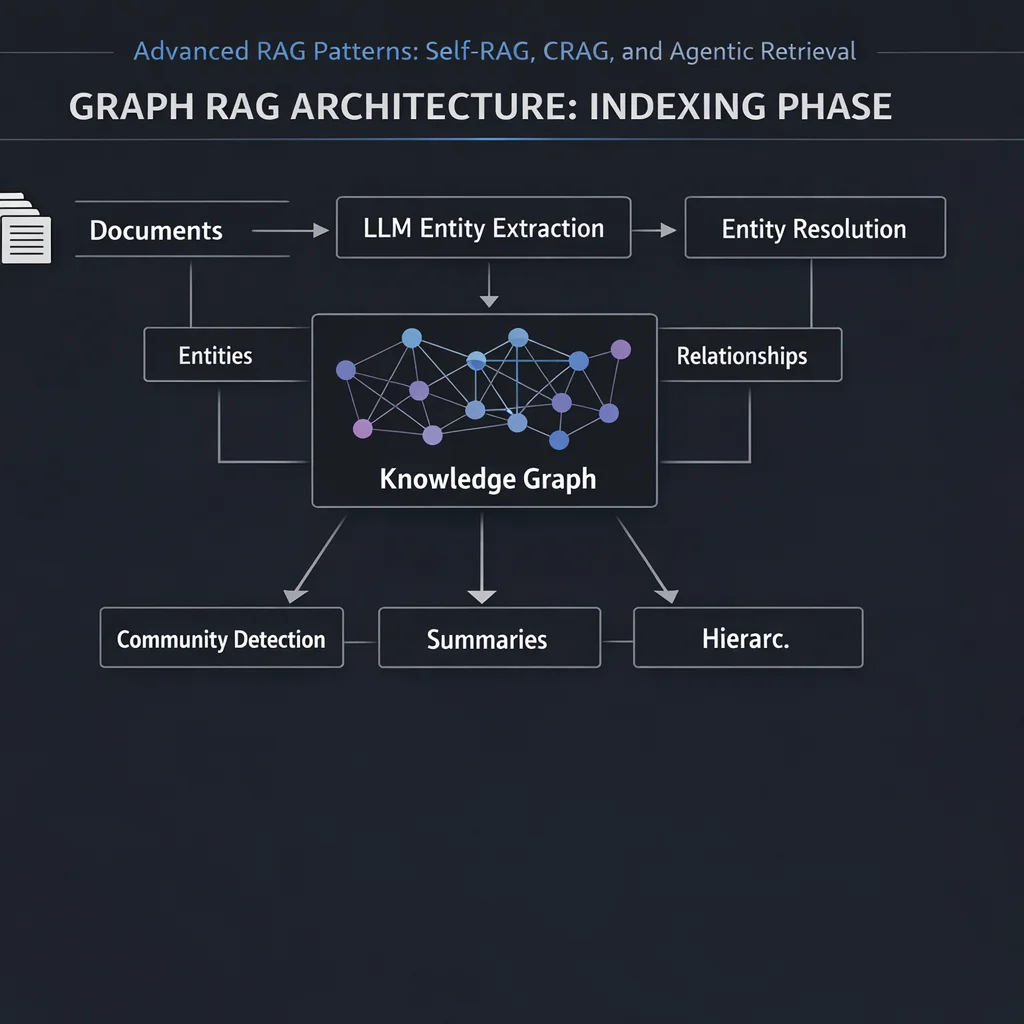
"""Graph RAG: Knowledge graph + vector retrieval hybrid."""
import networkx as nx
from dataclasses import dataclass
@dataclass
class Entity:
name: str
type: str # Person, Organization, Project, etc.
description: str
@dataclass
class Relationship:
source: str
target: str
relation: str # manages, works_on, depends_on, etc.
class GraphRAG:
def __init__(self):
self.graph = nx.DiGraph()
self.llm = ChatOpenAI(model="gpt-4o", temperature=0)
def extract_entities_and_relations(self, text: str):
"""LLM extracts entities and relationships from text."""
# Returns: entities[], relationships[]
pass
def local_search(self, query: str) -> dict:
"""
Local search for specific entity queries:
1. Extract entities from query
2. Find matching nodes in graph
3. Extract 2-hop subgraph neighborhood
4. Combine with vector search filtered to those entities
"""
query_entities = self.extract_entities_and_relations(query)[0]
matched = [e.name for e in query_entities if e.name in self.graph]
# Get 2-hop neighborhood
subgraph_nodes = set(matched)
for node in matched:
subgraph_nodes.update(self.graph.successors(node))
subgraph_nodes.update(self.graph.predecessors(node))
return {"graph_context": self._format_subgraph(subgraph_nodes)}
def global_search(self, query: str) -> str:
"""
Global search for broad questions ("What are the main themes?"):
Uses pre-computed community summaries from Leiden algorithm.
"""
pass
def query(self, question: str) -> str:
is_global = any(kw in question.lower() for kw in
["overall", "main themes", "summary", "across"])
context = self.global_search(question) if is_global else \
self.local_search(question)["graph_context"]
return self.llm.invoke(f"Answer using this graph context:\n{context}\n\nQ: {question}")| Query Type | Best Approach | Why |
|---|---|---|
| "What is X?" | Vector | Semantic matching for definitions |
| "How does X relate to Y?" | Graph | Explicit relationship traversal |
| "What affects project Z?" | Hybrid | Need relationships + context |
| "What are the main themes?" | Graph (Global) | Community-level summaries |
| "Find documents about X" | Vector | Semantic similarity |
| "Who reported to person P?" | Graph | Structural query |
Entity extraction quality: The entire system depends on accurate entity extraction. In production:
Graph database choice: Common options include:
| Database | Strengths | Best For |
|---|---|---|
| Neo4j | Mature, Cypher query language, visualization | Enterprise deployments |
| NetworkX | Python-native, easy to prototype | Development, small graphs |
| Amazon Neptune | Managed, scales well | AWS-native architectures |
| TigerGraph | High performance, real-time | Large-scale analytics |
Indexing cost: Graph RAG requires multiple LLM calls during indexing:
For a 1000-document corpus with average 10 chunks per document, expect 20,000+ LLM calls during indexing. Budget accordingly.
When NOT to use Graph RAG:
Every advanced pattern adds latency:
| Pattern | Typical Latency Overhead |
|---|---|
| Basic RAG | Baseline (1-2s) |
| Self-RAG (1 iteration) | +1-2s per critique step |
| Self-RAG (3 iterations) | +4-6s total |
| CRAG with web search | +2-3s for web search |
| Agentic (3-step) | +3-6s for tool calls |
| Graph RAG | +1-2s for graph traversal |
| Multi-modal | +2-5s for image processing |
Mitigation strategies:

Agentic RAG is notoriously difficult to debug because:
Best practices for observability:
"""Observability for agentic RAG - trace every decision and tool call."""
class AgentTracer:
def __init__(self, trace_id: str):
self.trace_id = trace_id
self.events = []
def log_step(self, step: str, input_data, output_data, duration_ms: float):
self.events.append({"step": step, "duration_ms": duration_ms, ...})
def log_tool_call(self, tool: str, args: dict, result, success: bool):
self.events.append({"type": "tool_call", "tool": tool, "success": success, ...})
def log_decision(self, decision_point: str, options: list, choice: str, reasoning: str):
self.events.append({"type": "decision", "choice": choice, "reasoning": reasoning, ...})
def get_trace(self) -> dict:
return {
"trace_id": self.trace_id,
"events": self.events,
"summary": {
"tool_calls": len([e for e in self.events if e.get("type") == "tool_call"]),
"failures": len([e for e in self.events if e.get("success") == False])
}
}Use tools like LangSmith, Langfuse, or Phoenix for production tracing with automatic instrumentation.
Advanced patterns multiply LLM costs:
| Pattern | Approximate LLM Calls per Query |
|---|---|
| Basic RAG | 1 |
| Self-RAG | 2-4 (retrieval decision + generation + critique + possible regeneration) |
| CRAG | 2-3 (evaluation + refinement + generation) |
| Agentic | 3-10+ (depending on tool calls) |
| Graph RAG (indexing) | 2-5 per chunk (entity extraction + summarization) |
Cost optimization strategies:
These patterns are not mutually exclusive. Production systems often combine:
Start with the simplest pattern that addresses your core problem, then add complexity as needed.
To make these patterns concrete, here are scenarios where each pattern provides clear value:
Scenario: Internal documentation chatbot for a 500-person company.
Problem: Users ask questions ranging from "What is Python?" (no retrieval needed) to "What is our SOC 2 compliance status?" (must retrieve). The basic RAG system retrieves for every query, wasting resources on simple questions and sometimes pulling irrelevant documents for specific queries.
Solution: Self-RAG with retrieval decision:
Scenario: Support chatbot for a SaaS product with frequent feature updates.
Problem: Knowledge base becomes stale as features change. Customers ask about recent features that are not yet documented. Basic RAG retrieves outdated documentation and generates incorrect answers.
Solution: CRAG with web search fallback:
Scenario: Research tool for analysts who need to synthesize information across multiple internal databases and external sources.
Problem: Questions like "What is our competitive position in the European market?" require data from CRM, market research reports, competitor tracking, and financial databases. No single retrieval can answer the question.
Solution: Agentic RAG with specialized tools:
Scenario: Documentation search for hardware products with technical diagrams, assembly instructions, and specification tables.
Problem: Users search for "mounting bracket dimensions" but the answer is in a diagram, not text. Basic RAG returns text descriptions but misses the visual specification.
Solution: Multi-modal RAG:
Scenario: Audit tool that traces regulatory requirements to internal controls and documentation.
Problem: Auditors ask "Which controls address GDPR Article 17 (right to erasure)?" This requires understanding the relationship chain: Regulation -> Requirements -> Controls -> Procedures -> Documentation.
Solution: Graph RAG:
Advanced RAG patterns address the limitations of naive retrieve-and-generate:
| Pattern | Solves | Trade-off |
|---|---|---|
| Self-RAG | Hallucinations, unnecessary retrieval | +Latency from critique loop |
| CRAG | Poor retrieval quality, knowledge gaps | +Complexity from evaluation |
| Agentic RAG | Multi-step reasoning, complex queries | +Cost from tool orchestration |
| Multi-Modal | Non-text content (images, tables) | +Processing time for vision |
| Graph RAG | Relationship-based queries | +Indexing cost for graph construction |
The key insight across all patterns: retrieval quality matters as much as generation quality. Sophisticated prompting cannot fix garbage context.
If you are moving beyond basic RAG, here is a practical progression:
Week 1-2: Baseline Measurement
Week 3-4: Targeted Improvement
Week 5-6: Advanced Patterns (if needed)
Key metrics to track:
In the next article, we will cover RAG evaluation: how to measure retrieval quality, detect hallucinations systematically, and build evaluation pipelines that catch problems before production.
Problem: Self-RAG loops indefinitely
Problem: CRAG always falls back to web search
Problem: Agent uses wrong tools or calls tools excessively
Problem: Multi-modal retrieval misses relevant images
Problem: Graph RAG returns too much irrelevant context
If you have an existing basic RAG system and want to add advanced patterns, here is a low-risk migration approach:
Phase 1: Shadow Mode (1-2 weeks)
def rag_with_shadow_evaluation(query: str):
# Run existing pipeline
basic_result = basic_rag(query)
# Run evaluation in parallel (log only, don't affect response)
try:
quality = evaluate_retrieval_quality(basic_result.documents)
support_score = check_hallucination(basic_result.answer, basic_result.documents)
log_shadow_metrics(query, quality, support_score)
except Exception:
pass # Never let shadow evaluation break production
return basic_resultPhase 2: Soft Intervention (2-4 weeks)
Phase 3: Full Deployment (ongoing)
| Framework | Best For | Advanced Pattern Support |
|---|---|---|
| LangGraph | Complex agentic workflows | Excellent - native cycles, conditions |
| LlamaIndex | Quick prototyping | Good - SubQuestionQueryEngine, RouterQueryEngine |
| Haystack | Production pipelines | Good - Decision nodes, Agents |
| DSPy | Optimizable pipelines | Emerging - compile-time optimization |
| Microsoft GraphRAG | Knowledge graph RAG | Excellent - purpose-built for Graph RAG |
| Unstructured | Multi-modal ingestion | N/A - preprocessing only |
| Arize Phoenix | Observability | Traces for any framework |
| LangSmith | LangChain observability | Deep LangChain/LangGraph integration |
| Langfuse | Open source observability | Framework agnostic |
For most projects, we recommend:
Self-RAG Paper: "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection" (Asai et al., 2023)
CRAG Paper: "Corrective Retrieval Augmented Generation" (Yan et al., 2024)
Microsoft GraphRAG: github.com/microsoft/graphrag
LangGraph Documentation: langchain-ai.github.io/langgraph
ColPali Paper: "ColPali: Efficient Document Retrieval with Vision Language Models" (Faysse et al., 2024)
Series Reference: RAG Foundations for core concepts
Related Article: Knowledge Graphs for AI: Beyond Vector Search for deep dive on graph approaches
Discover more content: